Os Workers de IA, também conhecidos como Assistentes de IA, são sistemas baseados em inteligência artificial projetados para executar tarefas específicas, auxiliar em processos automatizados e melhorar a eficiência de diversas operações.
Mas você deve estar se perguntando se esses tais de Workers ou “assistentes” servem apenas para tecnologia? A resposta é não! Também podemos contextualizar workers para revisar nossos posts, responder comentários, responder e-mails, prospectar clientes, realizar vendas, pesquisar passagens aéreas, definir roteiros de viagens, dentre outras funções não tão básicas como se imaginava.
Nesse sentido, a grande sacada dos Workers é que eles possuem funções específicas e são ótimos em realizar tarefas. Pensando nisso, vamos nos aprofundar nessa tecnologia em um conteúdo criado em parceria com o Henrique Souza, Especialista em Arquitetura aqui na Vivo.
Boa leitura!

Henrique conta que durante esses últimos 16 meses, tem evoluído constantemente o aprendizado no modelo de Workers de LLM. Mesmo antes do ChatGPT lançar esses modelos, a Vivo já tinha implementado modelos de Web Workers com “consciências” que resolviam alguma ação específica, como escrever uma linha de código, escrever uma linha de teste ou ainda atividades relacionadas à arquitetura de software.
Uma vez que os workers estão contextualizados, vamos falar sobre os LLMs (Large Language Models) ou Modelo de Linguagem de Grande Escala em português, que já existem há alguns anos e estão evoluindo rapidamente em direção a workers de IA e fluxos de trabalho. Não entenda mal, os LLMs são ótimos, mas ainda não são eficientes em automatizar tarefas sozinhos, mas combinados com outras ferramentas, são uma maneira realmente eficiente de utilizar a inteligência geral dos LLMs, consumindo quantidades de dados de linguagem.
No entanto, o maior problema com os LLMs é sua tendência a se perderem (alucinação e inconsistência), e nunca sabemos quando os LLMs ou workers podem falhar. Já existem algumas medidas de segurança em torno dessas falhas, mas estamos longe de explorar todas as capacidades da inteligência geral dos LLMs.
De RAG para Works
A sigla RAG é um acrônimo para Retrieval-Augmented Generation. É um tipo de sistema semi-paramétrico, onde a parte paramétrica é o LLM e o restante é a parte não-paramétrica. Combinar todas as diferentes partes nos dá o sistema semi-paramétrico. Este modelo utiliza tanto a capacidade dos LLMs de gerar texto quanto a habilidade dos sistemas de recuperação de buscar informações relevantes em bases de dados externas.
Mas qual problema isso resolve?
A troca de índices (informações específicas nos LLMs) nos dá personalização, o que significa que não sofremos com desatualização e também podemos revisar o que está no índice. A fundamentação dos LLMs com esses índices significa que temos menos alucinações e podemos fazer citações e atribuições apontando de volta para a fonte. Então, em princípio, o RAG nos dá a capacidade de criar uma melhor contextualização para que nossos LLMs tenham um bom desempenho.
Sim, você leu o termo “alucinações”. Este é um problema comum nos LLMs quando as perguntas (prompts) não são bem formatadas e bem direcionadas. A LLM pode responder algo que não faz o menor sentido. Por exemplo, se perguntarmos “Por que no Brasil não temos problemas com baixas temperaturas?”, uma resposta alucinada poderia ser “Porque o Brasil está localizado na estratosfera”.
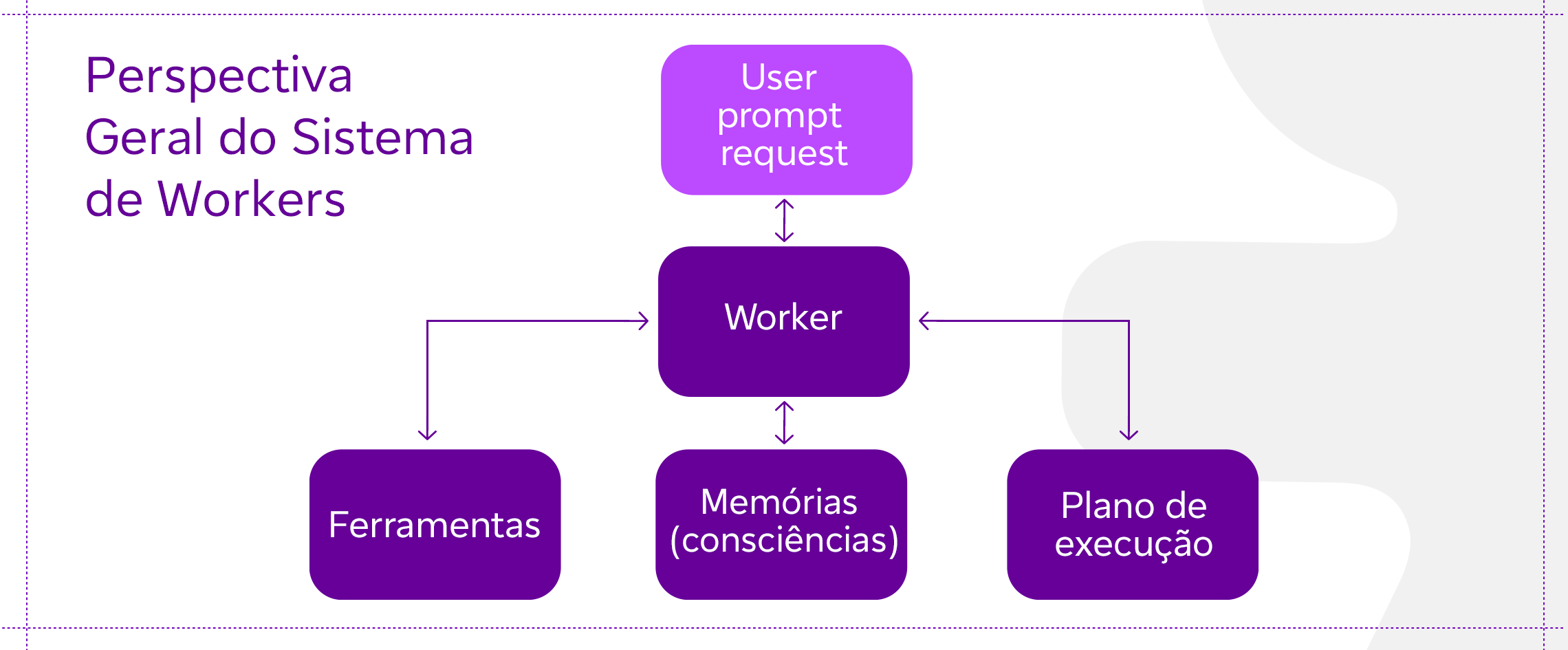
Perspectiva geral do sistema de Workers
Em um sistema de workers autônomos alimentado por LLMs, o LLM funciona como o cérebro do Worker, utilizando diferentes componentes para agir no mundo digital.
Uso de Ferramentas
O worker aprende a chamar APIs ou ferramentas externas para obter informações/ contextos extras ou capacidades que possam estar faltando nos pesos do modelo (geralmente difíceis de alterar após o pré-treinamento). Isso inclui coisas como informações atuais, motores matemáticos, capacidade de execução de código, acesso a fontes de informações proprietárias e muito mais.
Memória
Memória de curto prazo: o aprendizado em contexto (Engenharia de Prompt) pode ser considerado como o uso da memória de curto prazo do modelo para operar em um problema específico. A janela de comprimento de contexto pode ser considerada como a memória de curto prazo.
Memória de longo prazo: proporciona ao worker a capacidade de reter e recuperar (infinitas) informações ao longo de períodos prolongados, muitas vezes aproveitando um banco de vetores externo e recuperação rápida. A parte de Recuperação no RAG pode ser considerada como memória de longo prazo.
Planejamento
Decomposição de submetas e tarefas: o worker divide tarefas maiores em submetas menores e gerenciáveis, permitindo o manejo eficiente de tarefas complexas.
Reflexão e refinamento: o worker pode fazer autocrítica (embora duvidosa de certas maneiras) e autorreflexão sobre ações passadas, aprender com os erros e refiná-los para passos futuros, melhorando assim os resultados.
Uso de ferramentas para Workers de IA
Ser capaz de usar ferramentas é o que distingue os humanos de outras criaturas de muitas maneiras. Criamos, modificamos e utilizamos objetos externos para expandir nossas capacidades físicas e cognitivas. Da mesma forma, equipar os LLMs com ferramentas externas pode expandir significativamente suas capacidades.
No contexto de Workers de IA (inteligência artificial), as ferramentas correspondem a um conjunto de ferramentas que permite ao worker LLM interagir com ambientes externos, como Google Search, Code Interpreter, Math Engine etc. As ferramentas também podem ser algum tipo de bancos de dados, bases de conhecimento e modelos externos.
Assim, quando o worker interage com ferramentas externas, ele executa tarefas por meio de fluxos de trabalho que auxiliam o worker a obter observações ou contextos necessários para completar as sub tarefas dadas e, por fim, a tarefa completa.
Alguns exemplos de como as ferramentas são utilizadas de diferentes maneiras pelos LLMs:

Resolvendo problemas de memória em fluxos de trabalho de Workers
A memória pode ser definida como o recurso ou armazenamento usado para adquirir, armazenar, reter e posteriormente recuperar informações. Existem vários tipos de memória em qualquer sistema de computação.
Memória Buffer (Memória Sensorial)
Assim como a memória sensorial atua como um retentor breve (desaparece assim que a tarefa é concluída) para informações sensoriais, a memória buffer em sistemas de computador pode armazenar dados transitórios, como um conjunto de instruções. Para LLMs, isso pode se referir a buffers de tokens ou filas de entrada.
Memória de Trabalho (memória de curto prazo, STM)
LLMs, ao processar texto, empregam mecanismos que se assemelham à memória de trabalho humana. Eles usam mecanismos de atenção para manter o ‘foco’ em certas partes da entrada. Em modelos baseados em transformadores como o GPT, os pesos de atenção servem a uma função semelhante à STM, mantendo e processando várias peças de informação ao mesmo tempo. Memória de Trabalho para LLM é o comprimento do contexto dele.
Memória de Parâmetros (memória de longo prazo, LTM)
Os parâmetros (ou pesos) dos LLMs podem ser vistos como uma forma de memória de longo prazo. Uma vez treinados, esses parâmetros codificam vastas quantidades de informações extraídas dos dados de treinamento e podem ser retidos indefinidamente.
Memória Declarativa/ Explícita
Nos LLMs, o equivalente à memória declarativa seriam os pesos usados para gerar respostas baseadas em fatos e conceitos aprendidos. Estes podem ser acessados e usados para produzir saídas explícitas relacionadas ao conhecimento que o modelo ‘memorizou’ durante o treinamento. Por exemplo, “Elon Musk é o dono da Tesla”, isso é algo específico armazenado no peso do modelo.
Memória Procedural/ Implícita
Este é um sistema de memória mais generalizado que captura a abstração ou conceitos, em vez de fatos diretos, através da prática repetida (treinamento) em várias tarefas. Por exemplo, “o que é beleza?” Não há uma resposta específica para isso, e ainda assim o sistema será capaz de responder. Nos LLMs, as ‘memórias’ não são armazenadas como eventos discretos, mas são representadas como padrões (modelos de mundo abstratos, não totalmente) em uma rede de nós interconectados, e o modelo ‘recorda’ informações gerando dinamicamente respostas com base em seu estado treinado.
A memória externa pode resolver o problema da atenção finita. A prática padrão é salvar os vetores de incorporação (texto convertido em vetores densos) em um banco de dados de vetores que pode suportar a busca rápida de produto interno máximo (MIPS). Para otimizar a velocidade de recuperação, a escolha comum é o algoritmo de vizinhos mais próximos aproximados (ANN) para retornar aproximadamente os k vizinhos mais próximos para trocar um pouco da precisão perdida por uma grande aceleração.
Algoritmos para essa recuperação: LSH, ANNOY, HNSW, FAISS e ScaNN.
O princípio geral por trás de todos esses métodos — LSH, ANNOY, HNSW, FAISS e ScaNN — é aproximar de forma eficiente buscas de vizinhos mais próximos em espaços de alta dimensionalidade. Esses métodos são projetados para superar a intensidade computacional das buscas exatas usando estratégias que agrupam pontos de dados semelhantes juntos de uma forma que permite uma recuperação mais rápida.
Planejamento: o maior problema dos Workers de IA atuais
Os Workers, às vezes, podem fazer inúmeras chamadas para responder a uma única pergunta simples, acumulando tokens para cada consulta feita ao LLM. Isso não apenas é caro, mas introduz latência. A geração de tokens ainda é um processo relativamente lento; a maioria (não toda) da latência em aplicações baseadas em LLM vem da geração de tokens de saída.
Chamando um LLM repetidamente e pedindo para fornecer pensamentos/ observações, acabamos gerando muitos tokens de saída (custo), resultando em alta latência (experiência de usuário degradada).
Outro problema com workers de IA é que os LLMs são não-determinísticos. Embora benéfico para a geração de ideias, isso representa um desafio sério em cenários que exigem previsibilidade.
A partir das informações deste artigo, você pode perceber como as operações workers vêm sendo trabalhadas aqui na Vivo. Destacamos, principalmente, como isso influencia em projetos que envolvem a inteligência artificial.
Se você curtiu esse conteúdo e deseja aprofundar seus conhecimentos em IA, sugerimos a leitura do nosso e-book “Inteligência Artificial”, criado a partir da trilha de conhecimento dos profissionais da Vivo no The Developer’s Conference, o maior evento de tecnologia e inovação da América Latina.

Gostou do conteúdo? Compartilhe com mais pessoas.
Até a próxima. 💜